Best cell phone tracking app without permission
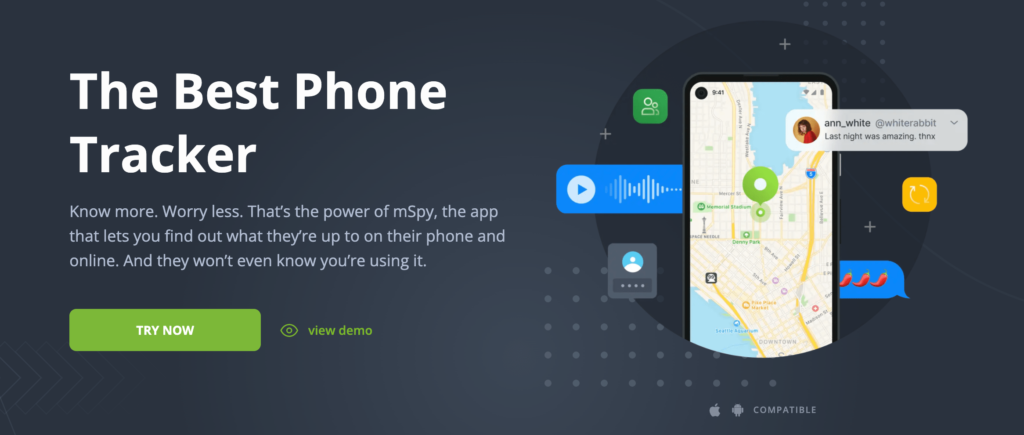
Having the best phone tracker app is an important part of staying safe in today's world. With so much personal information on our phones, it can be tough to know who has access to your most private data. The good news is that there are many options for phone tracker apps out there! We've compiled a list of some of the best ones below so you can find one that works for you and download them immediately.
Why do you need a phone tracker app?

Safeguarding your device from theft
Thousands of phones get stolen on a daily basis. However, you can prevent intruders from accessing your device by installing an effective phone tracker app (without permission) that promptly alerts you when someone else uses your phone. Such apps provide ample peace of mind to parents with school-going children because they offer real-time device tracking to ensure that kids are at school, daycare, or on their way home. You could also track your spouse’s phone in the unfortunate event that it’s stolen or lost. The most effective way to safeguard your phone from the prying eyes of burglars is by installing a dedicated phone tracker app on it immediately ─ ensure you download it now!

Catching a cheating partner
Most cheaters will never admit to having an affair, even when they’re confronted with hard evidence. Some might try to discredit your proof, while others could blame you for their unfaithfulness. Fortunately, you can utilize the best cell phone tracker application to monitor the cheater’s live GPS location and catch them red-handed. The app can also help you gather incriminating evidence of their affair, including call logs, text messages, emails, and internet searches. Once you show your spouse this solid proof, he/she will have no choice but to explain.
Keeping a close eye on your kids
It’s difficult to keep track of your kids every time. However, cell phone tracker apps can help you monitor their movements and view their phone activity throughout the day. Whether they are traveling home from school or simply playing in the park, installing a tracking app on their phones allows you to control their phone usage securely and remotely. The details you gather from such apps help you discover whether they’re browsing inappropriate content online or spending time in unsafe neighborhoods. You can even block unapproved apps installed on their phones with ease.
Why we choose mSpy as best cell phone tracking app without permissions
1. MSpy 🏆
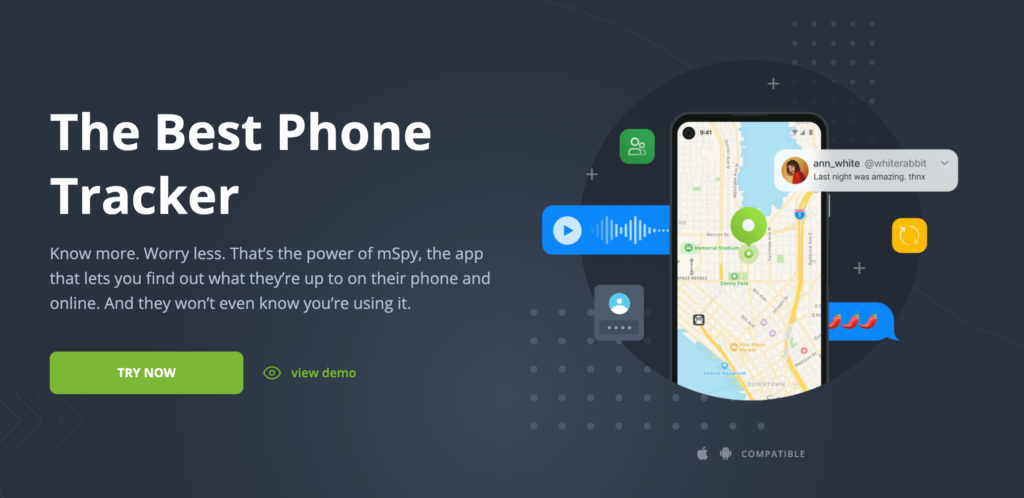
mSpy is one of the most popular cell phone tracker apps available, and it’s perfect for catching a cheater. This app has an assortment of bespoke tracking features and is compatible with both Android and iOS devices.
The main features:
- GPS tracking. You can easily track someone else’s phone AND view their real-time location using mSpy’s highly accurate GPS location tracker.
- Call and text monitoring. This app is equipped with a unique feature that reveals your target user’s call logs and SMS text messages. It operates in the background to avoid raising their suspicion.
- Social media monitoring (WhatsApp, Snapchat, Facebook, Twitter, Viber, etc.). Users can also monitor all chat conversations that their loved ones have with others on popular social media platforms. Shared photos and videos can also be viewed using mSpy.
- Email access data (Outlook.com and Gmail). Does your spouse use his/her email accounts often? You can see what exactly they talk about as well as recipient information using mSpy’s email tracking feature.
- App blocker (blacklist apps or phone features to prevent unauthorized phone use). Parents can easily block inappropriate apps that are installed on their children’s devices to prevent them from accessing violent or graphic content.

Price: $119.04/year subscription
Phone tracking app – main PROS of mSpy
- Complete confidentiality of data of all users
- Easy to download and set up the app
- Support for tracking all phone models and all operating systems
- 24/7 support that will help install or properly configure the phone at your request
Competitors
2. Moniterro.com

If you’re searching for a good phone tracking solution that’s easy to install and compatible with a wide range of devices, Moniterro can help. This cell tracking app is equipped with all the necessary features of a good monitoring app.
Moniterro comes with a built-in GPS tracker that reveals your target’s live location on a map. It also boasts of having a screen recorder that captures the screen of the phone being monitored. Those screenshots are then stored in the dashboard for your eyes only.
Other notable features that Moniterro offers include a keylogger that captures every keystroke that’s made on the target device and a browser history viewer that records each website your loved one visits during the day. These key features can help you understand whether your kids view/share sexually explicit content online.
You can also benefit from the app’s call recorder, instant messenger tracker, and website blocker.
Its main features include:
- Remote installation. This phone tracker app, that can locate without permissions, can be installed remotely on the target phone without having access to it. Moniterro.com offers an iPhone solution setup wizard that allows you to install an iOS device without jailbreak.
- Real-time location tracking. Its in-built GPS tracker really comes in handy whenever you want to view your loved one’s live location on a map.
- Call log and contacts viewing. Moniterro allows users to view other people’s call logs and contacts list. This info could reveal whether they’re interacting with the wrong crowd.
- Browser history monitoring. This feature shows you every website your loved one visits, including the frequency of those visits and timestamps.
3. Scannero
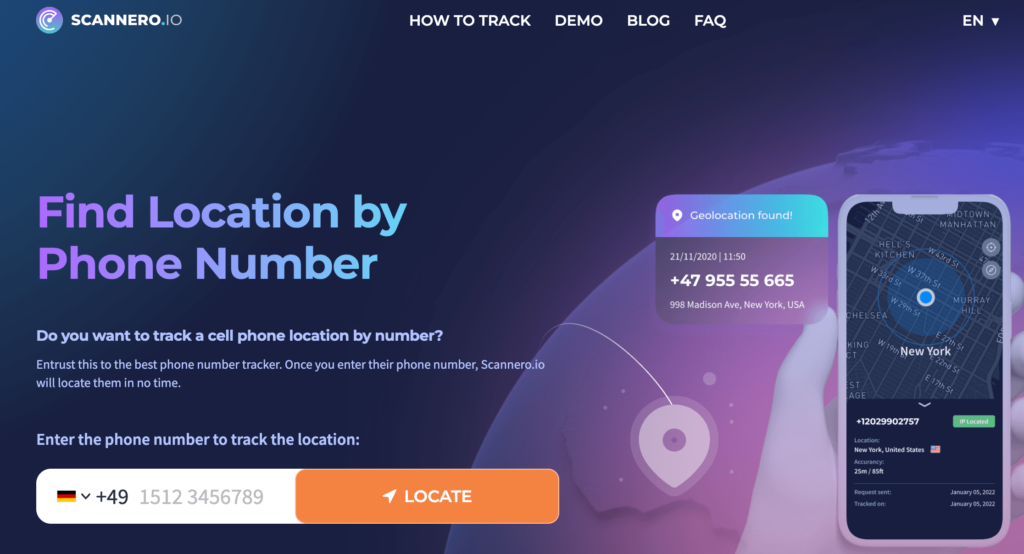
Scannero is a unique web-based cell phone tracker that can locate any type of device using its number alone. This geolocation tool works by sending a well-crafted message called a ‘hook’ to a target user. A tracking link is usually attached to this message.
When the recipient gets the message and clicks on the link, you’re able to view them on a map. Their location details, including the street address and accurate coordinates, are also displayed on the map.
Using Scannero to track a phone number is remarkably easy. You just need to visit https://scannero.io/ and type the number you wish to search on the empty field, then click “Locate.” Next, follow the instructions provided to view the person’s location.
Remarkably, this phone tracker works regardless of phone type, network carrier, or country. It’s also easy to use and provides individuals with several plans to suit their budget.
Main features:
- GPS location tracking data is available. If you’re interested in tracking your target’s real-time location throughout the day, this app comes with a precise GPS tracker that could help.
- Phone number lookup, phonebook access, etc.
4. Eyezy.com
Eyezy is another great cell phone tracker app without permissions that’s geared towards parents. It allows them to track their child’s location in real-time, view contact lists and messages, monitor internet activity, and more.
This app comes with a Social Spotlight feature that helps users to view other people’s private chats on WhatsApp, Snapchat, Tinder, Instagram, Facebook, and other popular social networking platforms.
Eyezy’s friendly installer allows you to install the app via iCloud sync, jailbreak, or local Wi-Fi sync. You can even view, control, and block what apps they use and websites they visit using its powerful connection blocker.
This app also comes with a Keystroke Capture feature that conveniently intercepts and stores every single keystroke your target user makes, allowing you to view their secret conversations and account login credentials.However, it does not have such extensive functionality when compared to its competitors. Also, it doesn’t provide a large number of payment methods.
The main features:
- Remote phone control. This phone tracker app allows you to control the target device from anywhere. You can view messages, block apps, and tap into their camera with ease.
- Social media monitoring. With Eyezy, you can track someone’s chat messages and shared media files on Instagram, TikTok, Facebook, Kik, Gmail, Signal, and a host of other social media sites.
- Call log history. Users can view who their loved ones call frequently using this feature. Eyezy also reveals the call duration and timestamps with great accuracy.
5. Haqerra

Would you like to hack another person’s phone within a couple of minutes? Haqerra promises to offer unrestricted access to your target user’s gallery, social media chats, call logs, contact list, and more without being detected.
Haqerra comes with a GPS tracker that shows you the exact location of any phone throughout the day. You can set designated zones on a map and get prompt alerts every time your loved one enters or exits these zones.
This app provides a variety of payment plans, and it operates in incognito mode to avoid spooking your target. The installation process is quite straightforward, thanks to Haqerra’s friendly user interface and intuitive functionalities.
If you’d like to spy on someone’s Facebook, Instagram, Snapchat, or Tinder chats, this app comes with social media monitoring features that can come in handy. It conveniently retrieves all private chats and group messages, storing them in a secure vault that’s only accessible to you.
Features:
- Calls made from phone can be tracked
- Text messages (SMS) sent from your phone can be monitored.
- Keylogger. This feature helps you to capture keystrokes on the target device, allowing you to view sent messages and account credentials.
- Gallery checker. With Haqerra, you’re provided access to all photos and videos stored on the target device.
- Phone call and surroundings recorder. This superb phone tracker app can record the target user’s phone conversations. It can also activate the phone camera/mic, allowing you to hear their surroundings.
- Instant alerts. You’re provided with 24/7 alerts whenever they use certain words in emails, SMS, browsers, and phonebooks.
6. Cocospy
Cocospy is a phone tracker app that’s great for catching cheaters. It has many of the same features as Mspy and Eyezy, but it also offers remote phone control to keep tabs on how your child uses their phone.
The main features:
- phone tracker app can be installed remotely on the target phone, without having access to it.
- real-time location tracking
7. Hoverwatch
Hoverwatch takes phone tracking one step further by allowing users to remotely view any activity going on in real-time through an online dashboard. They can even use this feature against their children or spouse if they want! Social media monitoring, call log history and GPS location data are all available with this phone tracker app.
The main features:
- remote phone control
- social media monitoring
- call log history
- GPS location tracking data are available
- phone number lookup, phonebook access etc.
A useful feature for this phone tracker app is the remote phone lock that can be used to remotely turn off someone’s smartphone if you suspect it has been stolen or you want to make sure that your phone is not being used in a way you don’t approve of.
8. XNSPY
Xnspy is another highly rated phone tracker app that allows you to track the calls made from your smartphone, including those not made through the phone’s built-in dialer. text messages, internet history, GPS location data and more can also be tracked with this app.
The main features:
- calls made from phone can be tracked
- text messages (SMS) sent from phone can be monitored.
9. FlexiSPY

Flexispy is one of the most powerful phone tracker apps on the market. It offers all of the features offered by other phone tracker apps as well as call recording, ambient listening and even keyboard monitoring to see what someone is typing on their phone.
The main features:
- Ambient listening. Wouldn’t you like to listen to your loved one’s surroundings every now and then? FlexiSPY has the ability to activate the target device’s mic and camera.
- Call recording. This app records each phone conversation your loved one makes and stores those recordings in the Control Panel for your review.
10. MobileTracker
MobileTracker is a phone tracker app that’s perfect for businesses who want to keep track of their employees’ whereabouts. In addition to GPS tracking and call log history, MobileTracker also monitors social media activity and email communications.
The main features:
- Call log history. You can conveniently view your employees’ call logs to discover whether they spend company time properly.
- Email access. Do your staff members use their corporate emails appropriately? This feature from Mobile Tracker can help you find out.
- Multimedia viewer. You can view photos and videos that are stored in the target device to check whether they’re sharing inappropriate content.
11. Snoopza
Snoopza bills itself as a phone tracker app for women. They can use it to track their partner’ activity on a phone and even keep tabs of his whereabouts through real-time GPS tracking.
This app can also be used to track your workers and children without raising their suspicions. It contains a variety of features that might come in handy if you’re searching for a basic phone monitoring solution.
The main features include:
- Track phone activity. Snoopza detects SIM card replacements and sends prompt alerts via email.
- Real-time GPS tracking. You can check other people’s live location and view their route history using the app’s GPS tracker.
- Internet history monitoring. This fantastic feature reveals every website your child/partner visits and what type of content they view.
- Taking screenshots. Snoopza takes snapshots of the target phone at regular intervals, helping you to intercept vital info.
12. FamiSafe
FamiSafe is another phone tracker app that’s designed with parents in mind. It monitors all phone activity, including calls, texts, and internet usage, so you always know where your children are at any given time.
The internet is rife with fraudsters, criminals, and child molesters whose goal is to lure unsuspecting users into their deadly snares. Having a powerful parental control app such as FamiSafe allows parents to carefully monitor their children’s smartphone usage with ease.
Its main features include:
- GPS location tracking. FamiSafe allows users to track their kids’ location on a map. They can view their coordinates and street location with remarkable accuracy.
- Monitor phone calls and texts. This app comes with a distinct feature that lets you monitor the target’s SMS messages, call logs, and social media chats.
- Monitor internet usage. You can track down the amount of time your children spend on the internet.
- Setting screen time limits. FamiSafe can develop a family media plan to prevent your kids from spending too much time on their phones.
13. Spyic
Spyic bills itself as the most powerful spy software available today because it tracks everything without needing physical access to someone’s phone or tablet device. All phone data like call logs, text messages, social media posts and more can be tracked remotely using this phone tracker app!
Once installed, this app operates in stealth mode to help you track someone else’s device without blowing your cover.
The main features of this phone tracker app include:
- No phone access required. You can monitor your loved one’s phone without invading their privacy.
- Track phone activity remotely. Spyic helps you to monitor the target phone’s messages, GPS location, and call logs from wherever you are.
- Calls made can be tracked and recorded (when allowed by law).
- Text messages sent and received can be seen in real time on the phone tracker app dashboard.
- GPS location data is available to show where a smartphone has been at any given point of time.
FAQ
Cell phone tracking software is a phone tracking app that can track phone calls, text messages, emails and even GPS location data.
Yes, you can use the phone tracker app to track any phone in the world as long as it has an internet connection and is turned on! The software cannot be installed directly onto someone’s phone so you need to know their phone number (and their phone needs to have service).
Yes, phone tracker apps are undetectable. They do not require any physical access to a phone or tablet so they cannot be detected by someone who knows what he’s looking for because there is nothing to detect!
A: Yes, phone tracker apps are completely legal in the United States and most European countries. They do not allow someone to invade anyone’s privacy because they only track phone activity that is already available publicly through phone company records or social media posts!
A: Mspy is absolutely the best phone tracking software because it’s undetectable, legal and offers a wide array of features that help you keep tabs on a phone without needing physical access to it.
MobileTracker phone tracker app is the best iPhone tracking software. It offers everything you need to keep tabs on an iPhone without needing physical access!
The absolute best phone tracker app without permission is Eyezy app because it offers everything you need to keep tabs on phone activity, including phone calls that can be listened to and recorded.
Phone tracking software enables parents who have teens with cell phones to track their whereabouts at all times so they know exactly where their children are when they’re out at night. Business owners can also use phone tracker apps to track their employees, so they know exactly where each person is at any given time!
The geofencing feature of phone tracking software lets you set up virtual boundaries on a map and receive an alert when the phone enters or leaves that area. This is a great way to keep tabs on someone’s whereabouts!
The main features of phone tracking software include call logging, text message monitoring, email monitoring, GPS location tracking, and social media post tracking. All of this information is available on the phone tracker app dashboard in real-time!
MSpy is the best phone tracking software because it’s undetectable, legal and offers a wide array of features that help you keep tabs on the phone without needing physical access to it. It’s also very affordable!
Important Features to Look for in a Mobile Phone Tracking Apps:
- GPS Location Tracking
With this function, you can track the phone on a map in real-time.
- Phone Call Recording
This function records all incoming and outgoing phone calls for future reference.
- Call Log History
All phone call logs are recorded and stored in the phone tracker app dashboard for easy access.
- Social Media Monitoring
You can keep an eye on all social media activity from the monitored phone. This includes posts, messages, comments, and more!
- Spy on Text Messages
The phone tracker app can spy on all text messages sent and received from the monitored phone.
- Internet Browsing History
See what websites have been visited on the monitored phone’s internet browser.
- Control Panel View
The control panel is where you go to access all the information collected by the phone tracker app. It’s a centralized location where you can see all phone activity at a glance!
How to Choose the Best GPS Phone Tracker
Ease of Use
Any phone tracker app worth its salt must be easy to use. You shouldn’t need an IT degree to install and operate a phone tracking software! Look for one that’s simple, intuitive and doesn’t require much effort on your part.
Device Compatibility
The best phone tracking app is one that’s easy to use and compatible with most phone brands. If the phone tracker app isn’t user-friendly, it defeats its purpose!
Available Features
When looking for a phone tracker app, make sure to compare the features offered by each one. The best phone tracking apps offer a wide range of features so you can track all aspects of phone activity!
Price
Phone tracker apps vary in price, so finding one that fits your budget is important. However, just because an app is cheap doesn’t mean it’s not worth the money!
Customer Support
If you have any questions or problems with the phone tracker app, be sure to check out the customer support options. Good customer support is essential for a good phone tracking experience!
Conclusion
When it comes to phone tracking, MSpy is the best option because it’s reliable, affordable, and easy to use. It offers a wide range of features that let you track all aspects of phone activity! So if you’re looking for a phone tracker app that delivers, look no further than Mspy!